Kepler.glをJupyterNotebook上で扱ってみた
今回はJupyterNotebook上でKepler.GLを触ってみたいと思います。Kepler.glとはUber社が開発した大規模データのビジュアライズツールです。Webサービスとして(アカウント登録なしで)も利用できるため、ぜひ気軽に触ってみてください。
さて今回は、そんなkepler.glをPython上で扱ってみたいと思います。
目次
前提条件
本記事の前提要件は以下の通りです(前回までの記事からいきなりハードルを上げてしまってすみません・・・)
- Python3.6以上の環境を導入済
- Pandasを導入済(操作方法も習得済)
- JupyterNotebookの実行環境を用意済(Pythonを始めとする言語を実行するためのツール)
パッケージの導入
必要なパッケージを導入します。導入はpipで一発です。
pip install keplergl
pip install geopandas
pip install sodapy元データの準備
Kepler.glで使うデータを用意します。今回は、G空間情報センター(有償・無償問わず、様々なGISデータを検索・ダウンロードできるサイトです)から、加古川市の公用車走行データをダウンロードして使います。
G空間情報センター https://www.geospatial.jp/gp_front/
上記ページのトップ画面、検索窓から「加古川市 走行データ」などで検索してください。

利用規約を確認のうえ、データをダウンロードします。今回は2017年の(加古川市_公用車走行データ(走行履歴)_2017.csv)をダウンロードしました。
また、このデータの中には複数のCSVファイルが入っています。今回はKepler.glを試すことが目的なので、このなかで任意の1ファイルだけを使用したいと思います。下記のように、Desktop直下に1ファイルを移動させました(以降、このファイルのデータを可視化の元データとして使います)。
Pythonでの操作
さて、Python(今回はJupyterNotebook上で実行します)上で、Kepler.glを用いて、先ほどダウンロードした車両データを可視化したいと思います。
各種ライブラリの導入
まずはKepler.gl、Pandasのライブラリをimportします。
#Kepler.glの導入
from keplergl import KeplerGl
#pandasの導入
import pandas as pd次に先ほど準備した車両データを読み込ませます。今回の元データはヘッダ行が存在しなかったため、header = None と指定したうえでpd.read_csv(CSVの読み込み)を行います。また、names = […]で、取り込みと同時にヘッダ名を付与します。
ヘッダ名を付与するとき、緯度はlat 経度はlonと命名しましょう。Keplear.glに限らず、多くのGISツールではlat,lonの列を座標情報として読み取る仕様になっています。
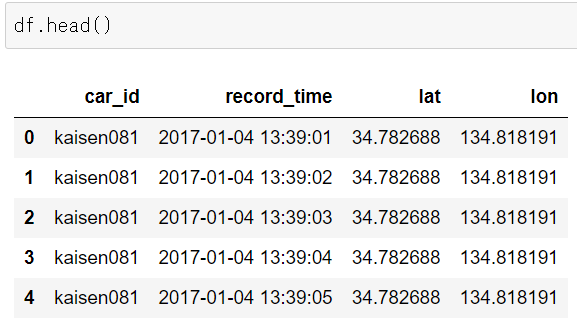
df = pd.read_csv('C:\Users\*****\Desktop\probe_kaisen081_2017.csv',header = None ,names=['car_id', 'record_time','lat','lon'])念のため、ちゃんと読み込み出来ていることを確認します。df.head()と打つことで、df(データフレーム)の中の先頭5行が確認できます。
ここまで出来れば、Kepler.glでの表示はスグできます!
map1 = KeplerGl(height=400)
map1.add_data(data=df, name='data1')
map1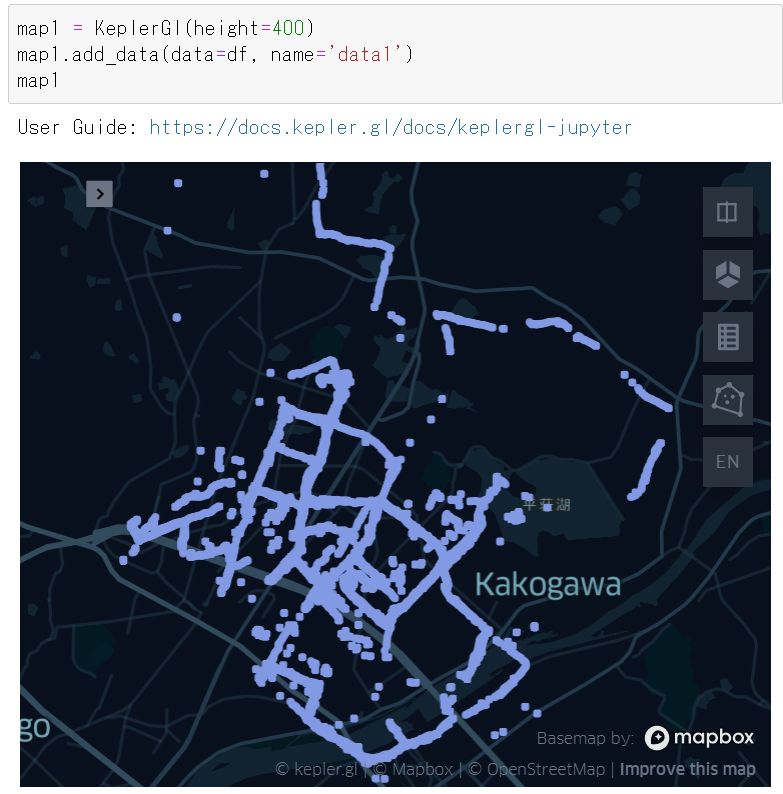
データが表示されました。今回用意したデータは 加古川市の公用車走行データ です。加古川市街を縦横無尽に走っていることが分かりますね!
可視化表現のカスタマイズ
可視化の表現はメニューから変更できます。
メニューバーは左上の「>」を選択すると表示されます。
またメニュー内のPointの欄の「∨」を押すと、ポイントレイヤの設定欄が出てきます。
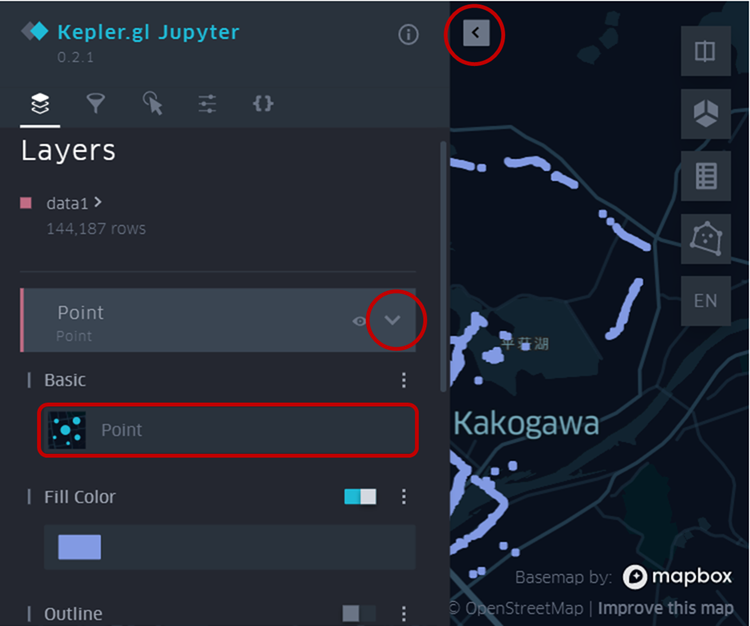
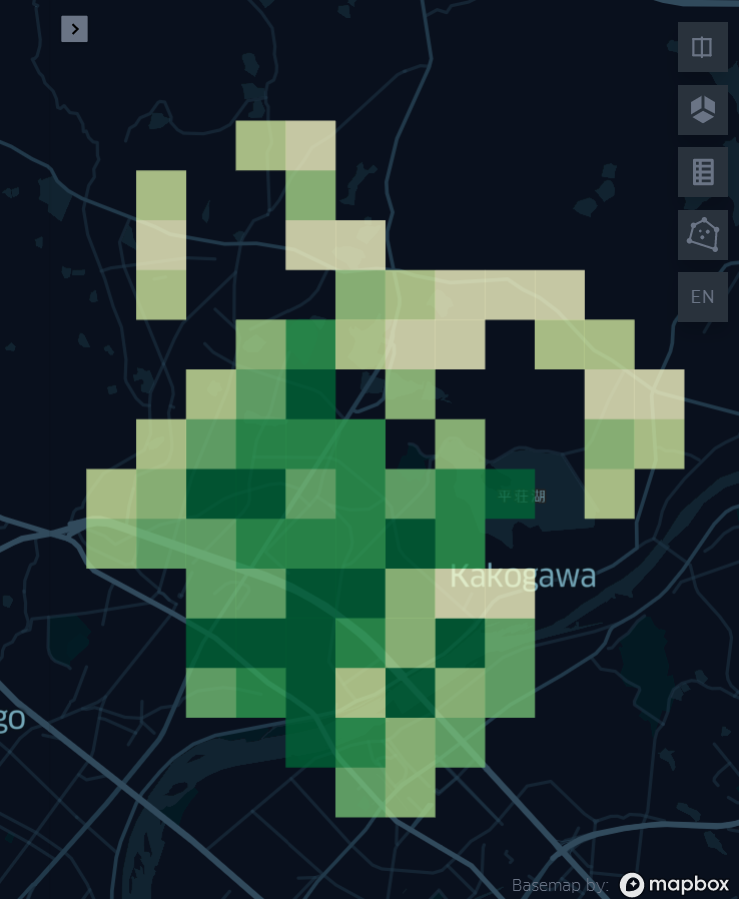
例えば上の図ではBasic欄が「Point」となっていますが、これを「Grid」に変更します。
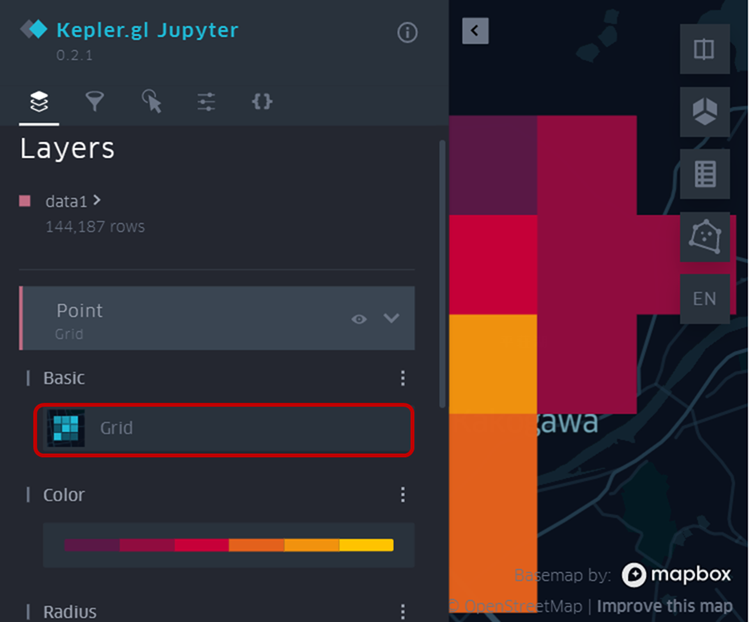
メニューバーを閉じると、下図のように表現が変わっています。色の明暗でポイントの多さが分かります。下図の場合、色の明るい場所(黄色みがかっている場所)ほど車両走行の多かった場所となります。
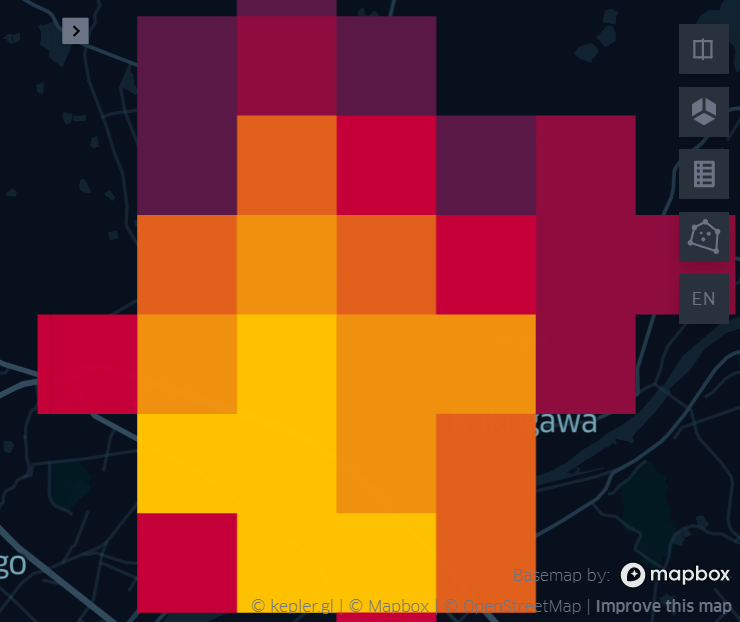
メニューバーの設定を色々と操作することで、同じデータでも様々な表現を作りだすことができます。
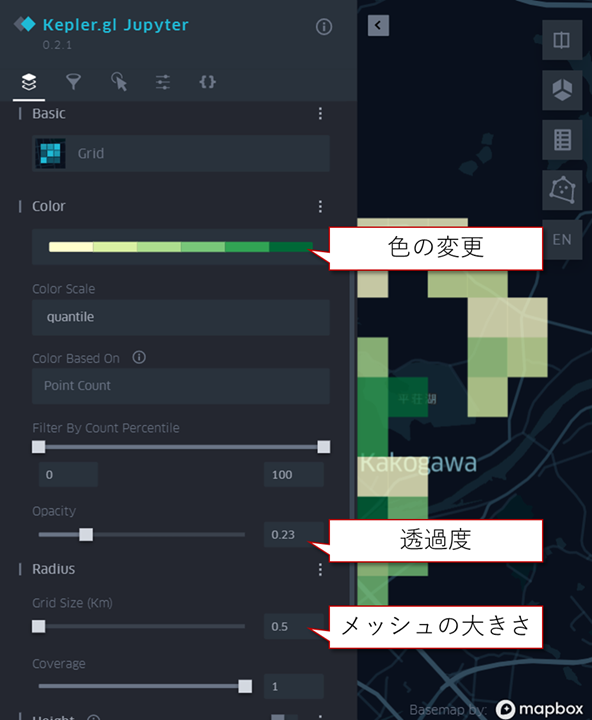
設定の保存
カスタマイズした表現方法は、保存することができます。保存しておけば、同じ表現で違うデータを可視化する…などの使い方ができます。例えば、加古川市の車両データは車両ごとにデータが分かれているので、今回の車両データと同じ色表現を、違う車両データにも適用したいときなどに有効です。
メニューバーを開き「{}」ボタンを選択します。するとMap Config というページが表示されます。この画面で「Copy」を選択してください。
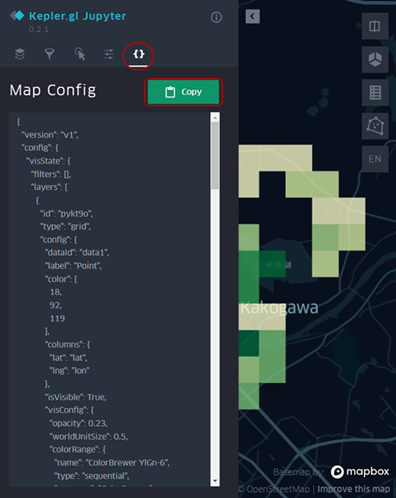
コピーしたMap Configのコードを、Python上の変数に残します。config = …(上でコピーしたコード)という形で変数に残します。
config = {
"version": "v1",
"config": {
"visState": {
"filters": [],
"layers": [
{
"id": "pykt9o",
"type": "grid",
"config": {
"dataId": "data1",
"label": "Point",
"color": [
18,
92,
119
],
・
・
・
#(コピーしたコードがあまりに長いので、以下は割愛します)今回保存した表現を用いてデータを可視化したいとき、地図を表示するコードを記述するとき、下記コード3行目のようにconfigの変数を読み込ませます。
1点注意として、下記コード2行目で、読み込むデータに対してname=’data1’とデータ名を与えていますが、この名称は先ほどと同様に指定してください。上のconfigの中身では、先ほどのデータ名(data1)に対して色などを定義しているため、データ名が異なるとconfigの定義が適用されなくなってしまいます。
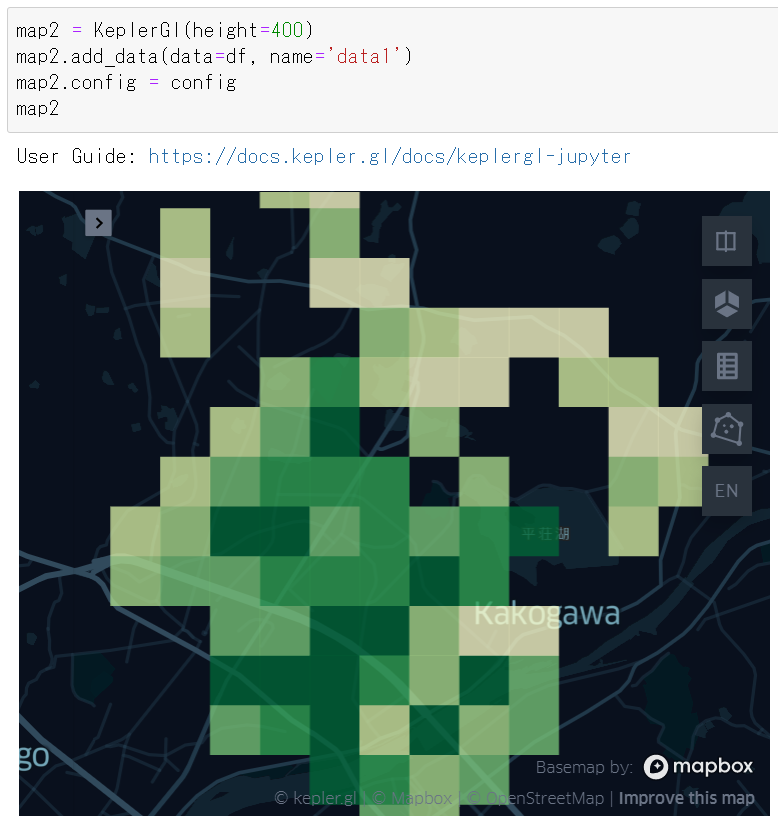
map2 = KeplerGl(height=400)
map2.add_data(data=df, name='data1')
map2.config = config
map2先ほどと同じ表現で、データが表示されました。
htmlファイルへの出力
さて、最後に、これまで作ってきたデータをhtmlファイルに出力する方法を紹介します。やり方は非常に簡単です。次のようにsave_to_htmlでhtmlファイルの保存先を指定します。今回はデスクトップ直下にfirstmap.htmlの名称で保存します。
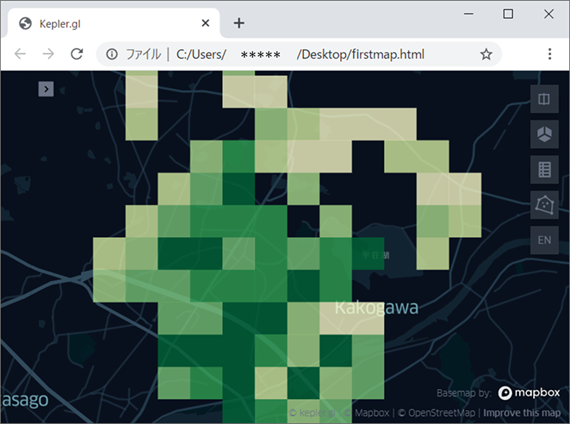
map1.save_to_html(file_name='C:\Users\*****\Desktop\firstmap.html')デスクトップ直下にhtmlファイルが作成されました。
htmlファイルを開いてみます。下図のように、今まで作成したマップが表示されるはずです。htmlファイルにすることで、同じデータを後で見返したいときや、他PCとシェアしたいときに簡単に閲覧することができますね。
おわりに
今回はKepler.glを扱ってみましたが如何でしたでしょうか。Kepler.glは元々配車サービスのUberが開発したとあって、位置情報データ、特に走行データの表現が非常に簡単に行うことができます。表現方法も様々用意されていて有難いです。
今回はメッシュ表現を例に一連の操作を紹介しましたが、ぜひ皆さんのお手元でも様々な表現方法を試してみてください!
本ページで扱ったデータは以下の著作物を改変して利用しています。
加古川市_公用車走行データ(走行履歴)_2017、加古川市、クリエイティブ・コモンズ・ライセンス表示2.1日本(http://creativecommons.org/licenses/by/2.1/jp/)